企业级零代码大模型全生命周期训练与优化平台,作为核心的 AI 能力引擎,打破大模型定制的技术壁垒,连接通用大模型与行业化智能应用。让企业无需依赖专业算法团队,即可基于自有数据快速构建适配业务场景的专属 AI 模型。
产品特点
-

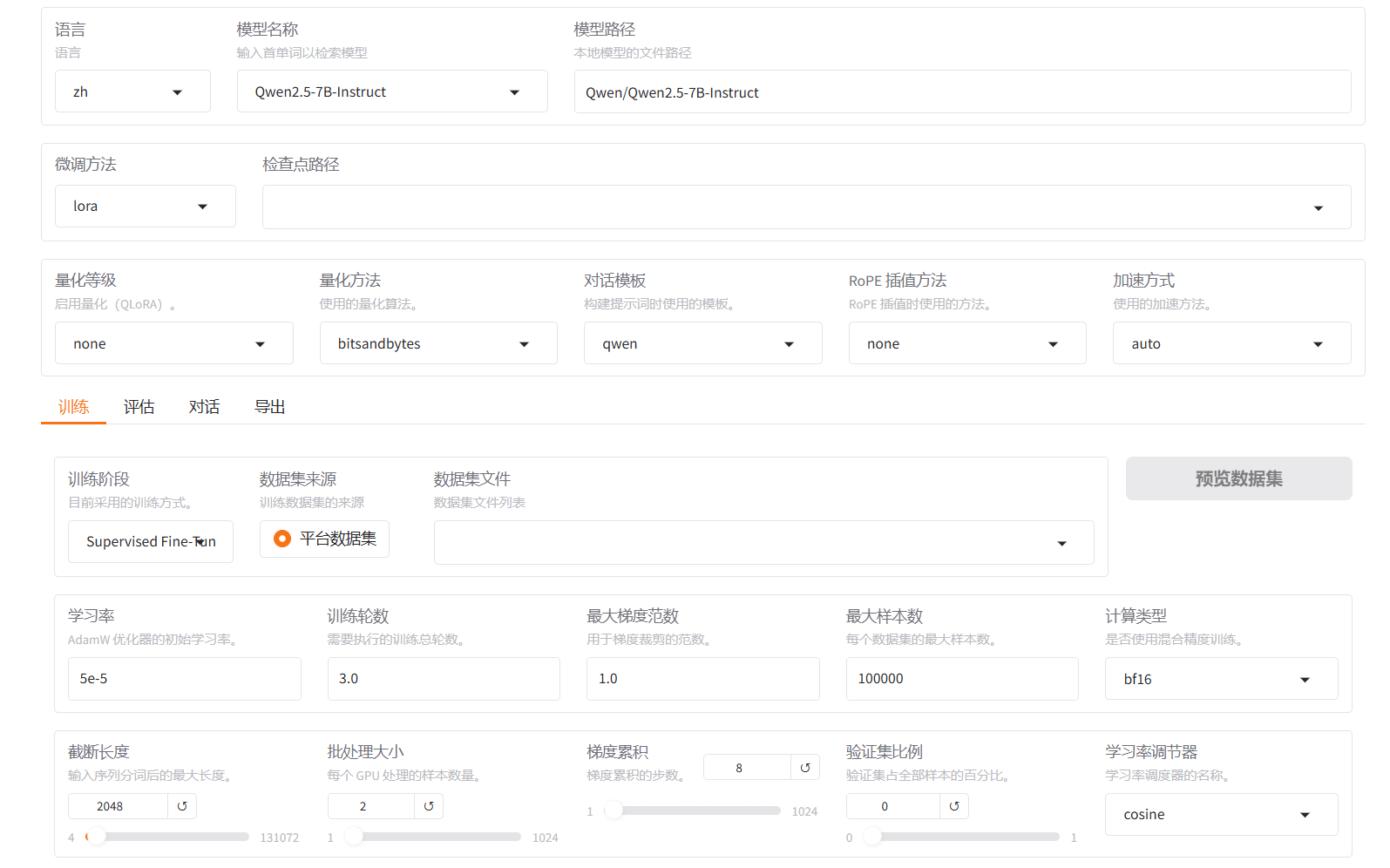
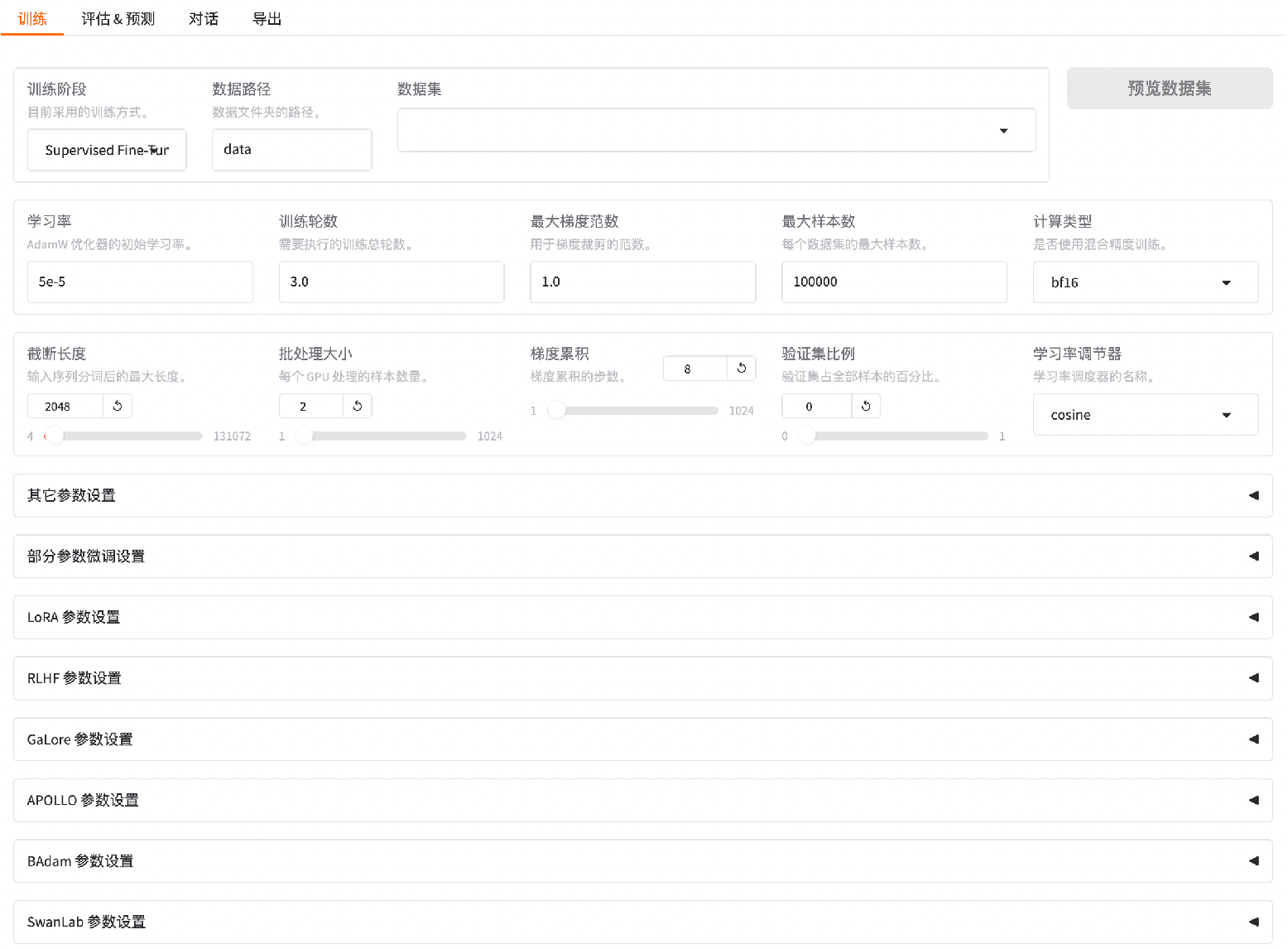
全流程训练能力覆盖
支持从(增量)预训练、多模态指令微调至 RLHF 全流程(奖励模型、PPO/DPO/KTO 训练等),适配各类场景需求
-

轻量化高效微调
通过 LoRA 等参数高效配置,大幅减少参数量与计算存储成本,平衡性能与资源消耗
-

人性化对齐优化
提供 RLHF 参数精细化配置,结合多种优化算法,使模型输出贴合人类价值观与业务需求
-

低门槛与高适配性
零代码 AutoML 工作流设计,兼容主流模型架构与国产芯片,兼顾技术深度与易用性
-

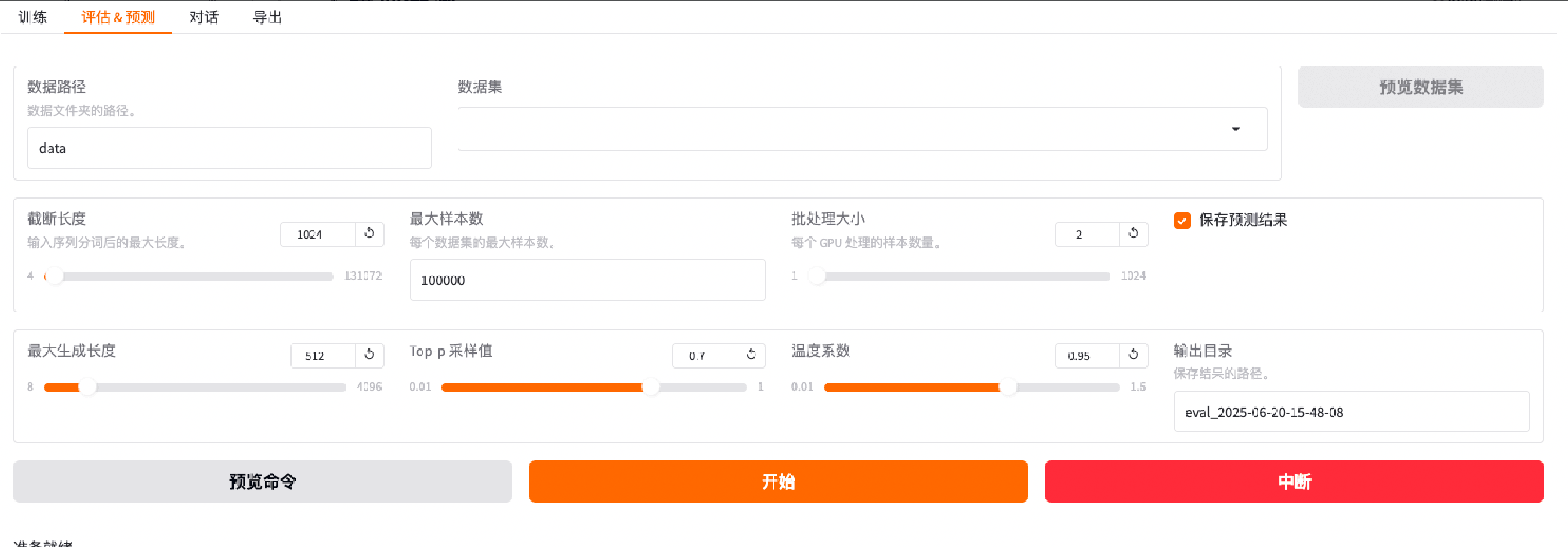
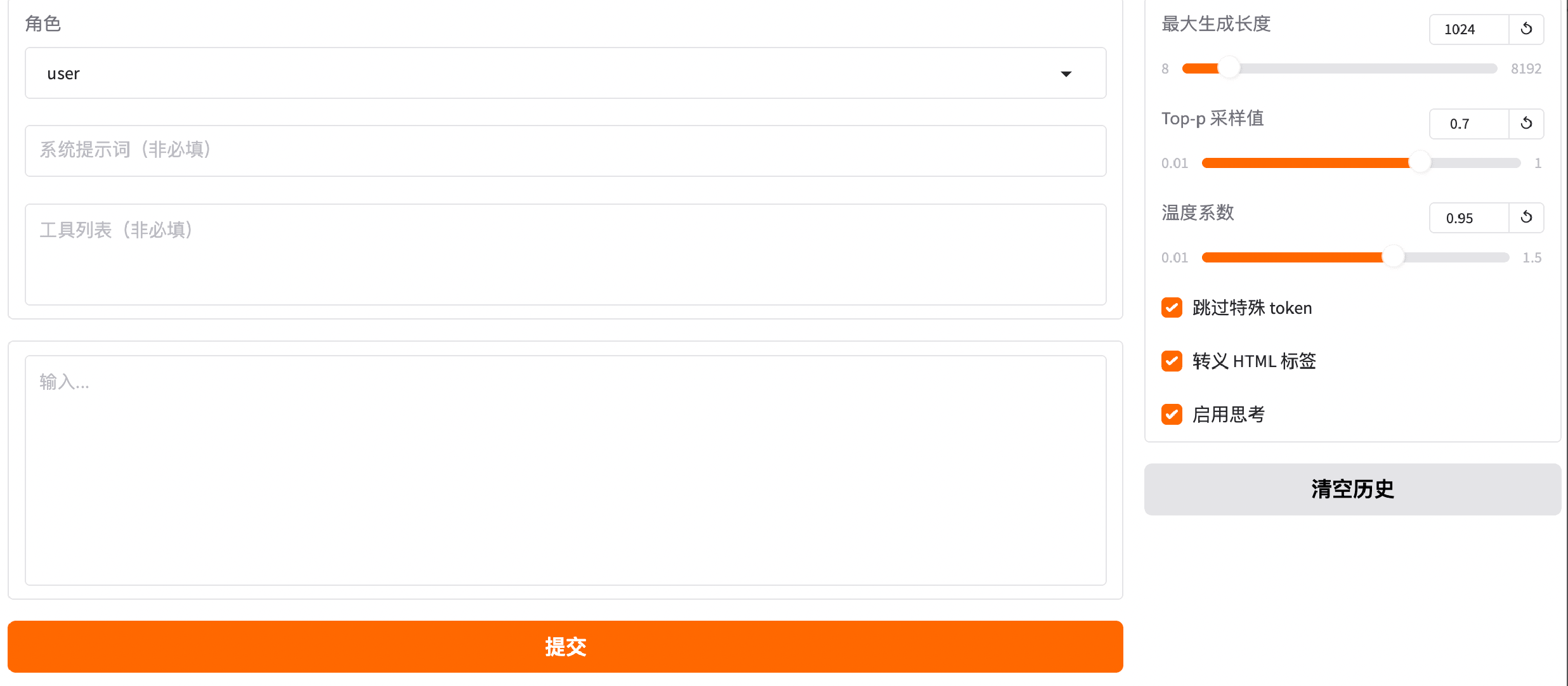
便捷试验场,即测即验
平台提供轻量在线测试环境,覆盖对话、图像、语音等多种模态,可快速验证模型推理效果。同时支持同批数据下多模型并行对比,模型表现直观可视,辅助调优决策。
-

本地与在线双模式灵活部署
支持一键导出模型包,适用于本地离线环境或边缘设备部署,同时支持在线发布,满足生产环境实时调用需求,两种模式自由切换,兼顾开发测试与业务接入。
功能介绍
全链路训推一体化
统一完成模型训练、微调与在线推理,一站式完成模型生产上线。
多组对照试验场
并行开展多版本调参实验,指标实时可视化,高效筛选最优模型。
标准化模型资产库
统一存储、分类、权限管理各类模型,支持便捷搜索与资产复用。
全域算力资源管控
实时查看GPU/CPU算力、内存、API调用、任务负载等全维度资源运行指标,精细化统计算力使用消耗,全方位管控算力资源。
应用场景
-

垂直领域专业化任务
对于数据壁垒高的垂直领域,如:法律文书生成、药物分子设计等。这些领域通常拥有高度专业化的知识体系和术语,通用模型难以准确理解和生成相关内容,适合通过微调技术提升模型在特定任务中的表现。
-

高稳定性要求场景
对输出稳定性要求严苛的场景,如:设备故障诊断、代码生成等。这些领域模型输出的准确性和一致性直接影响系统的可靠性和安全性。微调技术可以使模型更好地适应特定任务,减少错误率,确保输出结果的稳定性。
-

敏感数据私有化场景
涉及敏感数据的私有化部署需求的场景,如:政府公文处理、银行合规审查。这些领域对数据安全和隐私有严格要求。在本地环境中对模型进行微调,既能满足定制化需求,又能确保数据不外泄。
携手科杰科技,构建
AI-Native时代 Data & AI 一体化平台
联系我们
技术支持:support@keendata.com
北京市海淀区东升科技园北街6号院10号楼11层
上海市浦东新区崮山路538号中港汇浦东大厦11楼1107房
深圳市福田区兴业银行大厦714
沙特阿拉伯王国,利雅得市,穆罕马迪亚区,法赫德国王大街8428号

关注科杰科技
科杰科技 版权所有 | 京ICP备19042122号-6




业务咨询(09:00-18:00)
技术支持
support@keendata.com